institutional repository
overview
when munson medical center needed a way to preserve and showcase the scholarly work of its clinicians, residents, and staff, nothing like this existed at the hospital. i researched, proposed, and architected the entire system — from software selection through database design, author submission workflow, and copyright policies.
the goal was to create visibility for research produced across all departments: a structured, searchable system where authors could self-archive through a mediated submission process and where the hospital's research output would be visible and discoverable. this work grew out of my role in the medical library — years of helping clinicians find trusted information under time pressure, running literature searches, and teaching evidence-based practice.
the problem
scholarly output at munson — articles, posters, presentations, book chapters — had no centralized home. work was scattered across personal drives, department folders, and email attachments. there was no way to browse, search, or showcase what the hospital's researchers had produced. institutional knowledge was being lost.
without a repository, the hospital couldn't answer basic questions: what has our cardiology department published? who authored this poster from last year's conference? where does a resident go to find examples of scholarly work from their specialty? the gap wasn't just storage — it was discoverability.
discover
i started by searching for author repository examples at other hospitals and academic institutions, surveying colleagues in the medical librarian network, and developing inclusion criteria for what types of knowledge assets should be included. i reviewed 13 software platforms across open source, proprietary, and institutional options.
i then surveyed hospital staff for inclusion criteria and knowledge asset priorities — what they'd want to find in a repository and how they'd want to browse it. those findings shaped both the software evaluation and the schema design that followed.

define
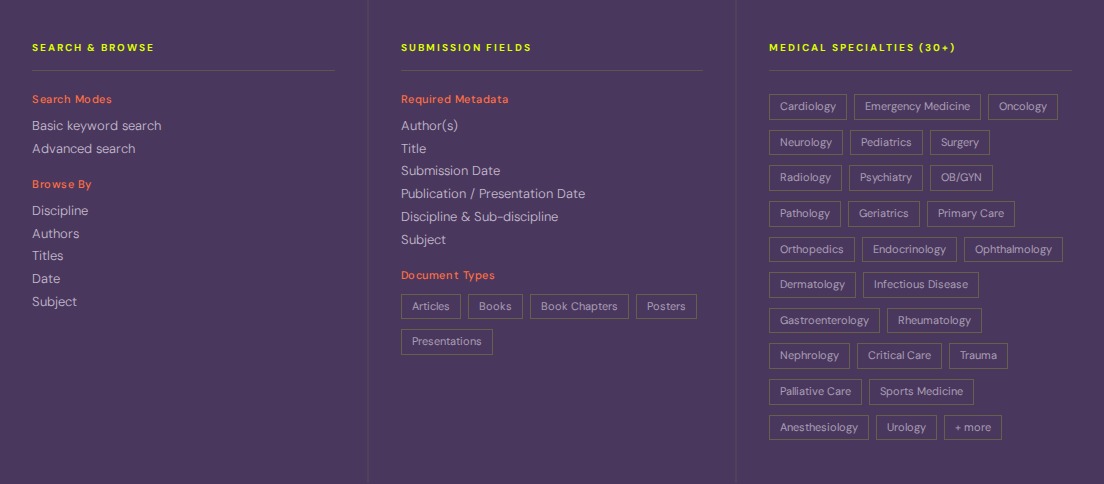
from the research, i designed the database schema, defined the submission workflow, and wrote the policies around copyright permissions and content types. the schema was built to support both browsing and precision search — with 30+ medical specialty classifications, multiple document types, and full metadata for every submission.
staff survey findings translated directly into browse paths: discipline and author were the highest-priority entry points, with subject and date supporting literature reviews and departmental showcases. required metadata covered authors, title, submission and publication dates, discipline and sub-discipline, and subject headings.
implement
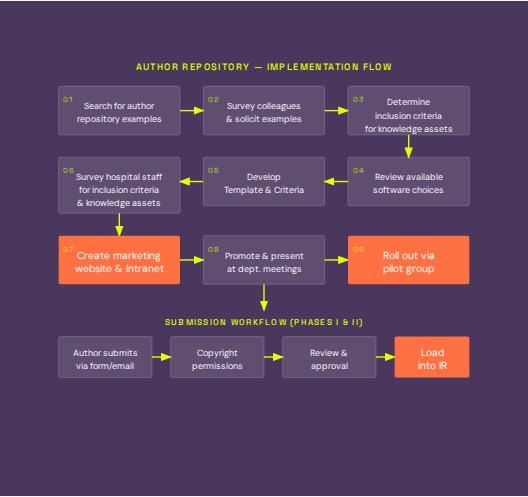
the implementation was planned in four phases: foundation (software selection and policy), content build (adding initial submissions), go-live, and evaluation. the rollout included creating a marketing website and intranet presence, presenting at department meetings, and launching via a pilot group before scaling self-archiving across departments.
the submission workflow ran from author submission via form or email through copyright permissions, review and approval, and loading into the repository. policy documentation covered submission process, content eligibility, copyright permissions, and the workflow itself.

reflection
this was the project that taught me how to think about information systems from the ground up. not just "where does this content go" but "who needs to find it, how will they look for it, and what happens when the system needs to grow." those questions have shaped every project since — from enterprise Workday workflows to patient-facing healthcare UX.
the staff survey was the turning point. i could have designed a schema based on library standards alone, but understanding how clinicians and researchers actually wanted to browse hospital output changed the browse paths, the metadata priorities, and the rollout plan. information architecture isn't just taxonomy — it's meeting people in the way they already look for things.